Consider utilizing a map that shows the wrong highway routes and omits multiple states when you are planning a cross-country road trip. What would be your level of confidence in getting to your destination quickly, or at all? This is exactly what happens when companies base their decisions on substandard data.
The digital economy of today has made data “the new oil.” But before raw data can support wise business decisions, it must be refined, much like crude oil must be refined before it can power engines. Better data, not more data, is frequently what makes the difference between success and failure.
What Is Data Quality?
Fundamentally, data quality is the degree to which a dataset fulfills its intended function. Consider it similar to water quality: water that is safe for irrigation may not be fit for human consumption. Likewise, information necessary for one business function may not be sufficient for another.
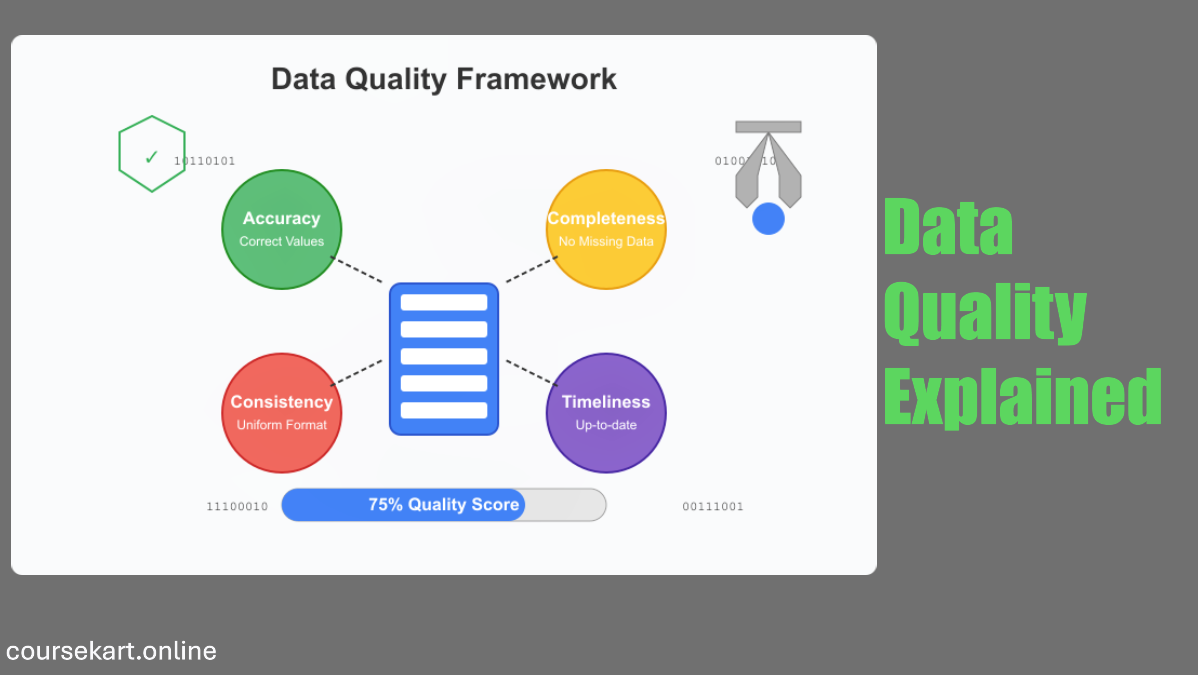
Six crucial traits, sometimes referred to as dimensions, are present in high-quality data:
Accuracy
Is your data accurate? Accurate data accurately depicts the facts, much like precise measurement equipment. Accuracy is demonstrated when a customer’s shipping address in your database corresponds to their real address.
Completeness
Do you have all the information you need? Having all the puzzle pieces is what it means to be complete. A customer profile without contact details is inadequate for its intended use, much like a dish lacking essential ingredients.
Consistency
Are your data points consistent across systems? Consistency is attained when a customer’s name appears exactly the same in both your billing and CRM systems.
Timeliness
Is your info up to date? Timeliness quantifies how current the information is. When making decisions about the supply chain today, last year’s inventory numbers are not very useful.
Validity
Does your data follow the business rules and the necessary formats? Legitimate email addresses include the @ symbol and domain extension, while legitimate phone numbers have the appropriate number of digits.
Uniqueness
Does each entity have a single representation? Duplicate customer records might result in distorted analytics or duplicate shipments, which are obvious indicators of compromised uniqueness.
Clean Data, Smart Decisions: The Hidden Value of Data Quality
Why Is Data Quality Crucial In The Digital Age?

The contemporary digital environment has never raised the stakes for data quality more than it does now. The following points state why data quality is so important in the digital age.
Impact On Decision Making
The speed at which today’s leaders make judgments is unparalleled. While inadequate data results in mistaken tactics and resource waste, quality data allows for confident, evidence-based decisions.
Gartner estimates that companies lose an average of $12.9 million a year as a result of poor data quality.
Role in Automation and AI
Systems that use artificial intelligence are prime examples of the “garbage in, garbage out” theory. AI reproduces—and frequently magnifies—pre-existing faults when it is trained on weak input.
When trained on a non-diverse dataset, a facial recognition system will inherit those biases, which could lead to large-scale biased results.
Effects on Business Operations
Accurate information flows are essential to operations, ranging from customer service to inventory management. Manufacturing errors happen when departments have different product specifications.
Customer support agents offer pointless answers when they access out-of-date account information.
Customer Trust
In a time when consumers are becoming more concerned about their privacy, data inaccuracies indicate negligence.
When a business consistently misspells a customer’s name or sends them offers that aren’t relevant to their needs, trust is damaged, and the profit is affected.
Real World Consequences Of Poor Data Quality

Poor data quality has practical, sometimes disastrous, effects across businesses that extend far beyond theoretical debates.
In marketing, inadequate data management can result in serious privacy and trust violations. One famous instance involves a large store that unintentionally revealed a teenage girl’s pregnancy to her unwary family by sending her coupons for specific baby products.
Even while the data analysis was technically correct, the corporation neglected to take into consideration how sensitive the material was, which resulted in a major privacy violation and a negative public reaction.
Problems with data quality in the finance industry can have billion-dollar repercussions. The notorious “London Whale” trading scandal at JP Morgan Chase is a good example.
Due in part to inaccurate data and mistakes in their value-at-risk model, the bank experienced enormous losses, highlighting the importance of precise risk assessment in financial operations.
Data inaccuracies can also prove life-threatening in the healthcare industry. Inaccuracies in the transfer of patient data between systems led to a U.S. hospital giving out the wrong dosages of medications.
For a few patients, these data inaccuracies led to serious health issues, underscoring the importance of accurate and clean data in medical settings.
Bad data quality has crippling financial consequences. According to IBM, inaccurate data costs the US economy over $3.1 trillion a year. Up to 50% of knowledge workers’ time is frequently spent on data-related tasks at the organizational level, whether they are looking for trustworthy information, settling conflicts, or fixing mistakes. In addition to lowering productivity, this inefficiency raises operating expenses.
Damage to one’s reputation is still another serious concern. One of the major credit bureaus, Experian, once incorrectly marked thousands of customers as dead on their credit reports.
Those impacted experienced financial difficulties and loan denials as a result of these mistakes. In addition to the immediate consequences, Experian’s reputation suffered as people began to doubt the quality and dependability of its data systems.
Who Is Responsible For Ensuring Data Quality?

In a company, everyone has responsibility for data quality, but some jobs are more accountable than others. Coordinated efforts from several stakeholders are necessary to ensure accurate, dependable, and usable data; each stakeholder is essential to the larger data ecosystem.
Within particular domains, Data Stewards are responsible for maintaining the quality of the data. Setting standards, keeping an eye on compliance, and supporting programs that advance data consistency and correctness are their responsibilities. Their function is to close the gap between data governance procedures and business requirements.
Data Engineers help by creating robust data pipelines that include error-handling and validation tests. Assuring that data is appropriately ingested, converted, and stored throughout its lifecycle, their technical expertise serves as the foundation for data quality.
Data analysts often serve as the first line of defense when identifying problems. In their capacity as frequent users of data for reporting and insights, analysts are in a unique position to identify irregularities, highlight questionable trends, and voice quality issues that might otherwise go overlooked.
At the data entry stage, Business Users—such as field technicians, salespeople, and customer support agents—are essential. Because downstream processes are greatly impacted by the quality of data provided at the source, it is crucial that these users adhere to best practices and enter data accurately.
For any data quality program to be successful, Executive Leadership is essential. Efforts frequently stall without senior leadership’s support and dedication. A culture of accountability and continuous improvement is strengthened when the C-suite views data quality as a strategic necessity rather than just a technical problem.
Data governance, a systematic set of rules, guidelines, and standards that direct how an organization handles its data assets, is at the core of all these positions. In order to guarantee that data quality is maintained throughout the organization, effective data governance establishes procedures for accountability, explicitly defines ownership, and enforces quality standards.
How To Measure Data Quality?
This is particularly true for data quality: you cannot enhance what you do not measure. In order to achieve significant progress, companies must first set baseline metrics that measure the condition of their data.
Common data quality metrics provide insight into the reliability and usability of datasets as follows.
Error rates quantify the proportion of records with inaccurate or invalid data, like erroneous dates or email addresses.
The number of needed fields that are actually filled in is measured by completeness scores.
Duplication rates measure the percentage of records that make reference to the same actual item, which can lead to redundancy and confusion.
The alignment of data pieces across several databases or systems is verified by consistency measures.
Lastly, timeliness metrics evaluate the data’s currentness, including the average age of a record or how frequently it is updated.
Organizations usually employ a range of tools to track and control these variables.
Software for data profiling, such as Informatica Data Quality, IBM InfoSphere, and Talend, examines datasets to find trends, draw attention to abnormalities, and flag possible problems.
Structured documentation of data assets is provided by data catalogs like Alation and Collibra, which frequently incorporate quality indicators to assist users in evaluating dependability.
In order to visualize important data quality metrics and monitor progress over time, many businesses also design their own dashboards.
Data profiling is typically the first step in the process of measuring data quality. Analyzing datasets to comprehend their composition, linkages, and structure is part of this process.
Outliers, missing numbers, and format discrepancies are among the problems that businesses can find through profiling.
Organizations can monitor progress and uphold high data standards over time with the support of these findings, which serve as the basis for focused improvements.
Related: How to Visualize Data Like a Pro? Smart Strategies for Clear and Impactful Insights
Strategies To Improve Data Quality
Preventive and corrective techniques are the two basic categories into which quality improvement strategies usually fall. Though they function at separate phases of the data lifecycle, both are necessary to preserve excellent data quality.
Taking proactive steps to stop data problems before they affect systems is known as a preventative approach.
Among these is the use of input validation at the moment of entry, which includes checking date ranges or email formats to identify problems instantly.
It is also essential to train data entry staff so that everyone working with data is aware of acceptable practices and the value of accuracy.
Establishing explicit data standards and documentation that offers instructions on required fields, naming conventions, and formatting is another important task for organizations.
Additionally, forms and applications that incorporate automated validation criteria aid in uniformly enforcing these standards.
The goal of corrective techniques, however, is to address issues that already exist in datasets. Data cleansing is frequently the first step in this process, which standardizes formats, fixes errors, and eliminates erroneous values.
In order to reduce confusion and inefficiencies, deduplication helps remove redundant entries that can belong to the same real-world item.
Using trustworthy third-party sources, data enrichment can fill in the blanks where information is lacking. In conclusion, master data management (MDM) is essential for producing and preserving reliable, consistent “golden records”—one authoritative version of important data items like clients or goods.
Together, these techniques establish a complete framework for enhancing and sustaining data quality, ensuring that companies can trust their data for decision-making and operations.
Best Practices To Follow
Maintaining excellent data quality involves a combination of known best practices and contemporary technologies. These approaches not only repair existing issues but also help prevent new ones from forming.
Data cleaning is a core step in quality management. It includes fixing misspellings, removing redundant entries that might cause confusion and inefficiencies, and standardizing formats—for example, making sure all phone numbers follow a consistent pattern. Without frequent cleaning, even well-structured databases can become overloaded with outdated or erroneous information.
Related: The Importance of Data Cleaning and How to Do It Effectively?
Another essential ideal practice is validation. Businesses can identify and fix data entries that don’t make sense by putting business rules into place. Systems can be made to, for instance, reject future birth dates or identify irregularities, such as a delivery date that falls before the order date. Real-time data integrity is maintained with the use of these tests.
By ensuring consistency across datasets, standardization facilitates the integration and comparison of data from many sources. For frequently used data like addresses, product codes, and currency values, this entails developing standard forms; this is particularly crucial in businesses with several divisions or systems.
These days, a lot of businesses are using automation and artificial intelligence to improve their data quality initiatives. Traditional rule-based systems are unable to identify anomalies that are too subtle to be detected by machine learning techniques. Unstructured text data, such as service tickets or customer reviews, is cleaned and standardized using natural language processing, or NLP.
By identifying records that are most likely to include errors, predictive models assist in prioritizing quality checks, while auto-correction tools can correct frequent errors based on historical correction patterns.
In addition to maintaining cleaner data, firms can decrease human tasks and speed up decision-making processes by integrating these best practices with cutting-edge technologies.
Data Quality And Compliance
A significant driving element behind many data quality projects is regulatory restrictions. Adherence to these rules necessitates not just accurate and comprehensive data but also the capacity to rectify and efficiently handle it.
For instance, enterprises must guarantee the accuracy of personal data and rectify any inaccuracies upon request from a data subject under the General Data Protection Regulation (GDPR).
Comparably, in order to promote efficient care and safeguard patient privacy, the Health Insurance Portability and Accountability Act (HIPAA) requires healthcare providers to keep accurate and comprehensive patient records.
In the financial industry, banks must adhere to strict data quality criteria for risk reporting, with a focus on timeliness, accuracy, and completeness, as set forth by BCBS 239, which was created by the Basel Committee on Banking Supervision.
The California Consumer Privacy Act (CCPA), which prioritizes data quality and transparency and grants consumers the ability to access and update their personal information, is also very important.
There may be major consequences for noncompliance with these criteria. Companies risk facing legal repercussions if they are unable to respond to requests for data subject access or corrections within the permitted time limitations.
Incomplete or inaccurate regulatory reporting may result in penalties and harm to one’s reputation. Additionally, low-quality data increases the likelihood of data breaches by making it more difficult to find and safeguard important information.
Not being able to show a clear data lineage or efficient quality controls during an audit can further damage an organization’s reputation and compliance position.
Businesses are better equipped to satisfy regulatory requirements when they invest in established data quality procedures.
They demonstrate to regulators that they have robust control over their information assets by being able to promptly trace, rectify, and validate their data. In addition to improving audit readiness, this builds stakeholder and customer trust.
Future Trends: Where Data Quality Is Headed
Innovation in technology and the increasing complexity of contemporary data ecosystems are driving a rapid evolution in the field of data quality. Organizations’ perspectives on and approaches to managing data quality are changing as a result of several new innovations.
The increase in data observability is one example of this. This method, which was taken from IT operations, offers real-time monitoring tools to watch the health of data, much like application performance monitoring tools do to identify problems in software systems.
By detecting abnormalities, schema modifications, and freshness problems in real time, these observability platforms allow for speedier reactions and less downstream damage.
The use of DataOps techniques is another revolutionary trend. To increase the dependability and effectiveness of data pipelines, DataOps—which was inspired by DevOps—promotes automation, cooperation between engineering and data teams, and ongoing feedback loops. This change speeds up the organization’s delivery of high-quality data.
Quality management powered by AI is also becoming more popular. AI systems are now able to anticipate possible quality problems before they arise and provide proactive preventative advice, going beyond basic rule-based checks.
These clever tools lessen the need for manual intervention while assisting in scaling data quality initiatives.
A scalable substitute for conventional, centralized governance approaches, federated data governance has surfaced as data landscapes grow more dispersed.
With this strategy, teams share data ownership, while a central organization maintains uniform standards and supervision, enabling both control and agility.
Frameworks for data quality are increasingly incorporating ethical considerations. Data must now be fair, unbiased, and morally sound in addition to being technically right, particularly in the context of AI and machine learning, where training data greatly influences results.
Lastly, Data Quality as a Service (DQaaS) is expanding the availability of high-quality technologies. By combining quality management capabilities with data processing and storage services, cloud providers are enabling even smaller businesses to take advantage of advanced data quality solutions without having to make significant infrastructure investments.
Forward-thinking companies understand that data quality is a strategic advantage rather than just a back-end chore. Businesses are better positioned to stay ahead in increasingly competitive situations when they use high-quality data to inform their decisions more quickly and intelligently.
Conclusion
Data quality has evolved from a backend IT issue to a fundamental business requirement. In the data-driven world of today, businesses that view data as a strategic advantage are unique. Data that is clear, consistent, and trustworthy helps businesses make better decisions more quickly, spur innovation, and gain a real competitive advantage.
Poor data quality can have crippling costs, including lost opportunities, squandered resources, noncompliance, and damaged stakeholder trust. On the other hand, improving data quality requires a comparatively minimal effort that pays off handsomely. Every department, including marketing, finance, and operations, can benefit from even a little increase in correctness, completeness, and consistency.
There are a few essential measures that organizations should take to begin the journey towards data excellence. To start, perform a data quality assessment to determine areas of concern and learn about the present condition of your information assets.
After that, give quality initiatives top priority around your most important data pieces, which are those that facilitate crucial operations and decision-making. Additionally, it’s critical to incorporate quality checks into your data processes from the outset rather than implementing solutions after problems have gone downstream.
Establishing a shared accountability culture for data quality is equally crucial. Everyone has a part to play in preserving integrity, from senior executives to data entry workers. The development of scalable, sustainable data procedures is facilitated when quality is ingrained in the organizational attitude.
In the end, trust is the key to data quality. Whether you’re launching a new product, assessing risk, or customizing a consumer experience, confident action is built on accurate, fast, and trustworthy data. Companies that not only gather data but also handle it well will be the ones that succeed in the digital economy.
Keep in mind that the quality of the data that powers even the most sophisticated analytics and artificial intelligence solutions depends on it. Data quality should be your first priority, not an afterthought, as you work toward digital transformation.
FAQ
What is data quality in simple terms?
How accurate, comprehensive, trustworthy, and pertinent your data is is referred to as its quality. Businesses can improve their decision-making with high-quality data, yet inefficiencies and mistakes result from low-quality data.
What are the main dimensions of data quality?
Accuracy, completeness, consistency, timeliness, validity, and distinctiveness are among the crucial aspects.
Why is data quality important in business?
Reduced operational errors, enhanced customer experiences, improved decision-making, and regulatory compliance are all facilitated by high-quality data.
What causes poor data quality?
Human mistakes, antiquated systems, a lack of data standards, inadequate tool integration, and a lack of validation procedures are common culprits.
How can I improve the quality of my data?
Using data validation tools, eliminating duplication, establishing explicit data entry guidelines, routinely auditing your data, and training your staff are all ways to improve the quality of your data.
Are there tools that help manage data quality?
Yes. Ataccama, IBM InfoSphere, Talend, Informatica, and open-source alternatives like OpenRefine are examples of popular tools.
What is the connection between data quality and compliance?
Regulations that demand precise and timely data handling, such as GDPR or HIPAA, might be broken by poor data quality. Preventing legal and financial concerns is facilitated by maintaining data quality.
Share Now:
Related Articles
Top 10 Online Data Science Courses For Beginners
What Will You Learn In The Applied Data Science With R Specialization On Coursera?
Discover more from coursekart.online
Subscribe to get the latest posts sent to your email.